AI Agent as Urban Planner: Steering Stakeholder Dynamics in Urban Planning via Consensus-based Multi-Agent Reinforcement Learning
Authors
Kejiang Qian, Lingjun Mao, Xin Liang, Yimin Ding, Jin Gao, Xinran Wei, Ziyi Guo, and Jiajie Li
Highlights
- Introduces an adaptable MARL framework for urban planning optimized around stakeholder interests.
- Offers urban planners a versatile planning tool.
- Shows MARL’s efficiency in uncertain environments.
- Expands MARL’s real-world urban planning applications.
- Links AI theory with societal needs through human-centric solutions.
Background
In urban planning, land use readjustment plays a pivotal role in aligning land use configurations with the current demands for sustainable urban development. However, present-day urban planning practices face two main issues:
- Land use decisions are predominantly dependent on human experts.
- While resident engagement in urban planning can promote urban sustainability and livability, it is challenging to reconcile the diverse interests of stakeholders.
Aim & Methodology
To address these challenges, we introduce a Consensus-based Multi-Agent Reinforcement Learning framework for real-world land use readjustment.
- This framework serves participatory urban planning, allowing diverse intelligent agents as stakeholder representatives to vote for preferred land use types.
- Within this framework, we propose a novel consensus mechanism in reward design to optimize land utilization through collective decision making.
- To abstract the structure of the complex urban system, the geographic information of cities is transformed into a spatial graph structure and then processed by graph neural networks.
- Comprehensive experiments on both traditional top-down planning and participatory planning methods from real-world communities indicate that our computational framework enhances global benefits and accommodates diverse interests, leading to improved satisfaction across different demographic groups.
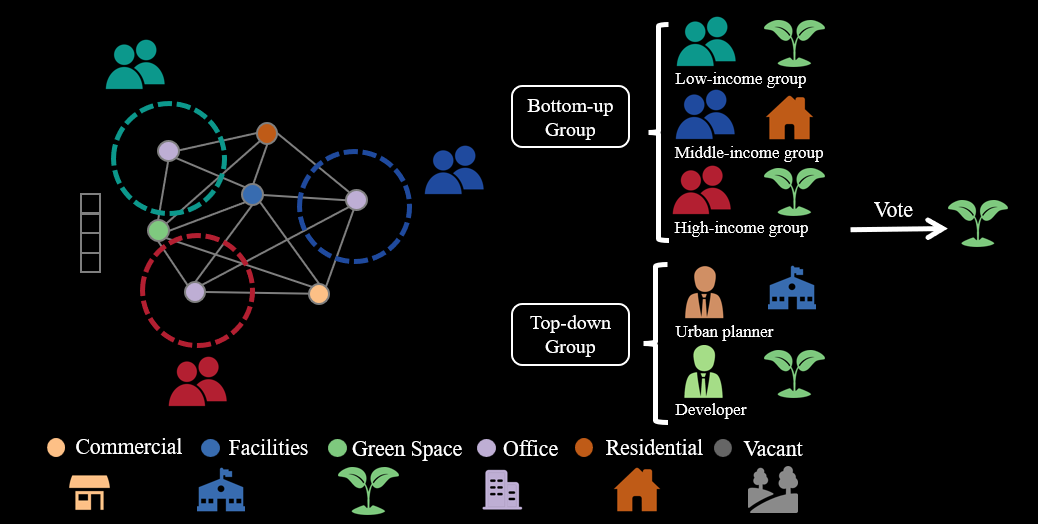
Figure 1: In the Consensus-based Multi-Agent Reinforce-ment Learning (MARL) framework, agents are distributed across different locations with varied observation ranges. Each agent casts a vote for its preferred land use type. The collective voting outcome determines the land use type to be readjusted in the corresponding urban parcel.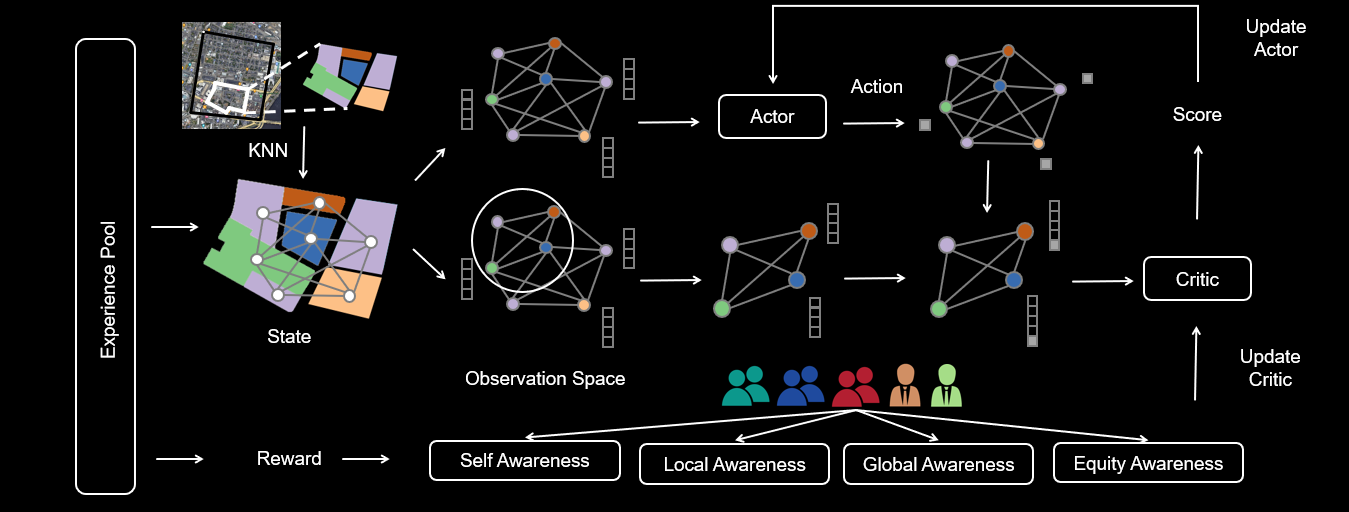
Figure 2: In our framework, we utilize the Actor-Critic architecture. The Actor processes an initial graph to generate an action. Conversely, the Critic takes a combined input of the initial graph and the Actor’s output, subsequently producing a score for the action in its current state.
Results
Planning outcomes
By integrating Multi-Agent Reinforcement Learning, our framework ensures that participatory urban planning decisions are more dynamic and adaptive to evolving community needs and provides a robust platform for automating complex real-world urban planning processes.
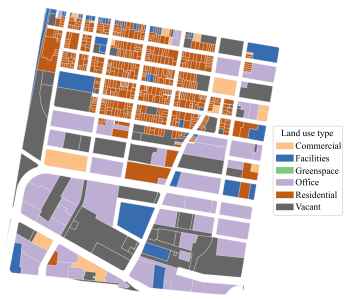
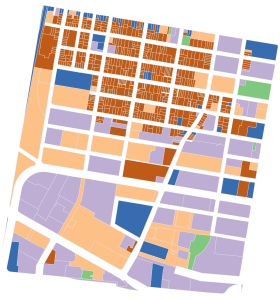
Baseline algorithm
In our study, conducted within both top-down and participatory planning environments, we select four methods as baselines for comparison: the random method, the greedy method, DRL and our proposed method. Specifically:
- The random method, Random Top-down Planning (Random-TP) and Random Participatory Planning (Random-PP), allows each agent to vote for a land-use type based on random selection.
- The greedy method, Greedy Top-down Planning (Greedy-TP) and Greedy Participatory Planning (Greedy-PP) enables agents to vote for the land-use type that is most beneficial to them individually, neglecting the global impact.
- The DRL method, DRL Top-down Planning (DRL-TP) is employed in top-down planning, centralizing decision-making of land readjustment.
Algorithmic metrics
To assess the performance of compared methods from an algorithmic standpoint, we focused on two key rewards, Global Reward and Equity Reward, derived from the reward metrics aforementioned: global awareness and equity awareness. Utilizing these metrics quantifies the capability of each approach to not only optimize land use distribution in alignment with overarching urban development goals but also to balance individual interests, emphasizing social equity in the decision-making process. Thus, we focus on maximizing the Global Reward and simultaneously minimizing the Equity Reward in the experiment.
Table 1: Algorithmic effectiveness comparisons
| Methods | Global reward | Equity reward |
|---|---|---|
| Random-TP | 0.958 | 36084.443 |
| Random-PP | 0.942 | 38697.276 |
| Greedy-TP | 0.965 | 42117.190 |
| Greedy-PP | 0.962 | 35328.027 |
| DRL-TP | 1.018 | 40532.082 |
| Our method | 1.018 | 28240.209 |
Urban metrics
Beyond the algorithmic metrics, the outcomes proposed by each method are assessed from urban planning perspectives, specifically examining the potential improvement in the quality of life for agents in the region. In the government planning guideline of Kendall Square, four planning metrics, sustainability, innovation, service, and diversity, stand out as crucial determinants of its planning targets.
Table 2: Urban metrics comparisons
| Methods | Sustainability | Innovation | Service | Diversity |
|---|---|---|---|---|
| Initial state | 0.11 | 0.36 | 0.39 | 0.82 |
| Random-TP | 0.19 | 0.48 | 0.38 | 0.82 |
| Random-PP | 0.15 | 0.47 | 0.39 | 0.82 |
| Greedy-TP | 0.17 | 0.47 | 0.38 | 0.81 |
| Greedy-PP | 0.17 | 0.48 | 0.38 | 0.86 |
| DRL-TP | 0.27 | 0.48 | 0.41 | 0.86 |
| Our method | 0.63 | 0.79 | 0.41 | 1.42 |
Paper link
View our paper: ArXivL:2310.16772